実臨床に役立てるメタアナリシスの読み方④ -Methods編中盤②-
今回もMethods~Resultsの一部にまたがって説明していきます。
前回の記事はこちら
実臨床に役立てるメタアナリシスの読み方① システマティックレビューとメタアナリシスの違い『なぜメタアナリシスのみはダメなのか』
実臨床に役立てるメタアナリシスの読み方② -Background編〜Methods編前半
実臨床に役立てるメタアナリシスの読み方③ -Methods編中盤①
まとめたページと参考文献はこちら(未完成)
今回は主に報告バイアス(reporting bias)と呼ばれるバイアスを中心に説明していきます。具体的には「網羅的な検索はされているか」「報告バイアスの検討がされているか」という観点から論文を見ます。これらは「批判的吟味」をする上で必須の情報で、ここに問題があればエビデンスの質が下がることとなります。
目次:
報告バイアスとは何か
報告バイアス(reporting bias)とは研究結果やその内容によって報告されやすいものとそうでないものの間に偏りがあることを指します。
例えば、治療の効果に有意差を示した新薬の研究とそうでなかった新薬の研究ではどちらが報告されやすいでしょうか。

図:有意差による研究の行方
それはもちろん有意差があったほうが、取り上げる学術雑誌も通りやすいでしょうし、より有名なIFの大きい雑誌に取り上げられやすいと言えます。(バイアスの問題点から、必ずしも最近はそうではない部分はあります)
しかしながら、こうした一定の傾向があらゆる研究に対して続くとどうなってしまうでしょうか。
結果が悪いものなどの一部が取り上げられなくなり、世に出回るのは結果の良い偏った研究結果のみとなってしまいます。
そうなると、過去の研究を集めて結果を出すメタアナリシスで問題が生じます。実際には効果がないものであったとしても、偶然に良い結果が出た研究ばかりが偏って集まってしまい、統合した結果、まるで効果があることが確実かのように見えてしまうわけです。
しかも、報告されていない研究を調べる術がなければそれは解決できません。報告されていない研究を探すことは通常難しく、不可能な場合もあります。このため、報告バイアスがメタアナリシスにおいて最も対処の難しい問題であるとされています。
ただ、可能な限りの対処方法は提案されているので、それが正しく行われているかどうかは確認が必要です。これは後述します。
その前にまず、報告バイアスと呼ばれるものには具体的にどのような種類があるか見てみます。
報告バイアスの種類
報告バイアスと一口に言っても、種類には色々あります。Cochrane databaseのページが参考になりますので、こちらの分類に沿ってごく簡単に紹介していきます。
Reporting Biases | Cochrane Bias
******
出版バイアス(publication bias)
最初に取り上げた例は出版バイアスに当てはまります。研究の内容や結果によって出版されるかどうかに偏りが出てしまうことを指します。結果については上述した通り、有意差の如何により、偏りが出る場合があります。内容については、すごくマイナーな疾患の研究だと、どうしても大きな雑誌には取り上げられづらいという点が指摘できます。
特に有意差の有無に着目しすぎて、有意差があるものが出版されやすく、そうでないものは出版されにくいということはよく問題視されています。検出力などもきちんと計算されている研究であれば有意差がないこと自体にもある程度意味は見出せるのではないでしょうか。
タイムラグバイアス(time lag bias)
「介入が有効だった」などのポジティブな結果の研究がより早く出版されやすく、そうでない研究は遅い、というバイアスです。また研究の内容によっても同様に違いが出ることがあります。
特に昨今だとコロナ関連の話題がとにかく早く出るのに、それ以外の研究は全然査読が進まない、というタイムラグバイアスは強く感じられるのではないでしょうか・・・。
多重出版バイアス(multiple publication bias)
同じ研究の結果が複数の雑誌で出版されることなどを指します。別のものとしてカウントされてしまうと、同じ結果のものが過剰に計算されることになります。
ロケーションバイアス(location bias)
ある研究に対するアクセスのしやすさが結果やサンプルサイズなどによって変わってしまうことを指します。サンプルサイズが小さいような研究はIFの低い雑誌になってしまう、というのが一つの例です。
また、文献のデータベースごとに含まれる研究の違いが出ることもあります。MEDLINEには載っているのにEMBASEに載っていない、など調べる媒体によって研究のあるなしが変わる時があるので、必ず複数のデータベースを調べる必要があります。
引用バイアス(citation bias)
論文の内容や結果によって引用のされやすさが変わる偏りを指します。どうしても、著者の持つ意見を支持するような論文を引用することになるため、有意差のあるような論文の方が引用されがちです。
言語バイアス(language bias)
調べる言語によって文献に偏りが出てしまうことを言います。基本的に英語で検索して出てくるような文献が見つかりやすく、他言語のものは見つけにくいという偏りが生じやすいです。
調べる側にその言語がわかる人がいないといけないので、これはなかなか大変ではないかと思います。メタアナリシスによっては日本語の文献まで調べているものもあります。なんとなく嬉しいです笑。
(選択的)アウトカム報告バイアス(selective outcome reporting bias)
研究のアウトカムの一部のみが報告され、それ以外は報告されないことがあります。例えば、有意差が出て、著者の仮説や意見を支持するものは数値も含めて載せられるけれど、そうでないものは詳細な数値が書かれず、“有意差はなかった”と載せられているのみ、という場合です。
******
とにかく沢山のバイアスがありますが、分類のされ方は文献によって多少異なることもあります。ロケーションバイアスという言葉に「言語バイアス」「引用バイアス」などが含まれている例もみられました。ただ、分類よりも大事なのは、目に見える研究というのは多数の影響を受けた上で選抜されてしまったものだと認識することです。
目に見える研究がこれだけ多くの影響を受けて選ばれていることを考えると、バイアスに対して何らかの対処を講じていく必要があります。「批判的吟味」として、その方法がきちんととられているかをチェックするわけです。
以下でその方法を見ていきます。
網羅的な検索がされているか
過去の研究の検索方法が本当に網羅的になされているかを見ていきます。
これは上記のバイアスのうち、出版バイアス、タイムラグバイアス、ロケーションバイアス、言語バイアスへの対処となります。
これらのバイアスをできるだけ避けるためには得られる限りの広い範囲で研究を集めなければいけません。研究のデータベースとしてはMEDLINE(普段よく使うPubMedは主にここから情報を得てます), EMBASEといったものから検索されることが多いです。
さらに研究中のものや、研究が終わったけれど論文化されていないものを探すため、ClinicalTrials.govのような各国の臨床試験の登録システム内の検索も行います。こうすることでタイムラグバイアスに多少なりとも対処ができます。
データが論文中に十分載っていないものもあるので、その場合は研究元に問い合わせをしてデータがないか確認します。
さらに場合によっては関連する薬剤を販売する製薬会社にデータを問い合わせたり、あらゆる手段を使って、知りうる限りの情報を集めます。
また、言語バイアスについては多数の言語で検索し、各国のデータベースにアクセスすることでカバー範囲が広がります。
通常のPubMedやGoogle scholarの検索で出てくる文献を探すのは、自分たちにもできてしまうことなので
・未発表の研究
・未発表のデータ
をいかにしてすくい上げるかが重要な点と言えるでしょう。
なお、サンプルサイズの大きい大規模な研究はこういったバイアスで報告されない、ということは起こりにくいと言われています。なぜなら、お金と労力をかけているので、たとえ有意差がなくても発表されやすいからです。またサンプルサイズが大きければ、検出力も高くなりやすいので、有意差がなくてもある程度意味を持つことができるからとも言えます。
それに対して小さい研究は報告バイアスの影響を受けやすいため、特に注意が必要です。小さい研究を集めて大きな対象人数にして発表された研究結果が、後の大規模RCTで覆されることもあります(具体例は実臨床に役立てるメタアナリシスの読み方①参照)。
報告バイアスの検討
さて、ここまで網羅的に頑張って検索しても、見つかる研究に偏りは生じます。
そこで次に必要なのは、集まった研究が実際に偏りがあるのかどうかを検討することです。
「存在しないものも含めて偏りがあるのかどうかなんて、そんなこと検討できるの!?」と思ったりしたのですが、方法としてはあります。
ただ、いずれも偏りがあるかどうか証明するには、どうしても限界がある方法です。これで問題なければ大丈夫、とは言えない点に注意が必要です。
どのような検討の方法をとっているかはMethodsに、その結果はResultsに書いてあるので、論文の質を「批判的吟味」する際には目を通すことをお勧めします。代表的な方法としてfunnel plotを見てみます。
funnel plotとは
funnel plotとは縦軸に標準誤差、横軸にアウトカムの対数オッズ比をとり、各研究をプロットしていく方法です。こんな感じの図になります。
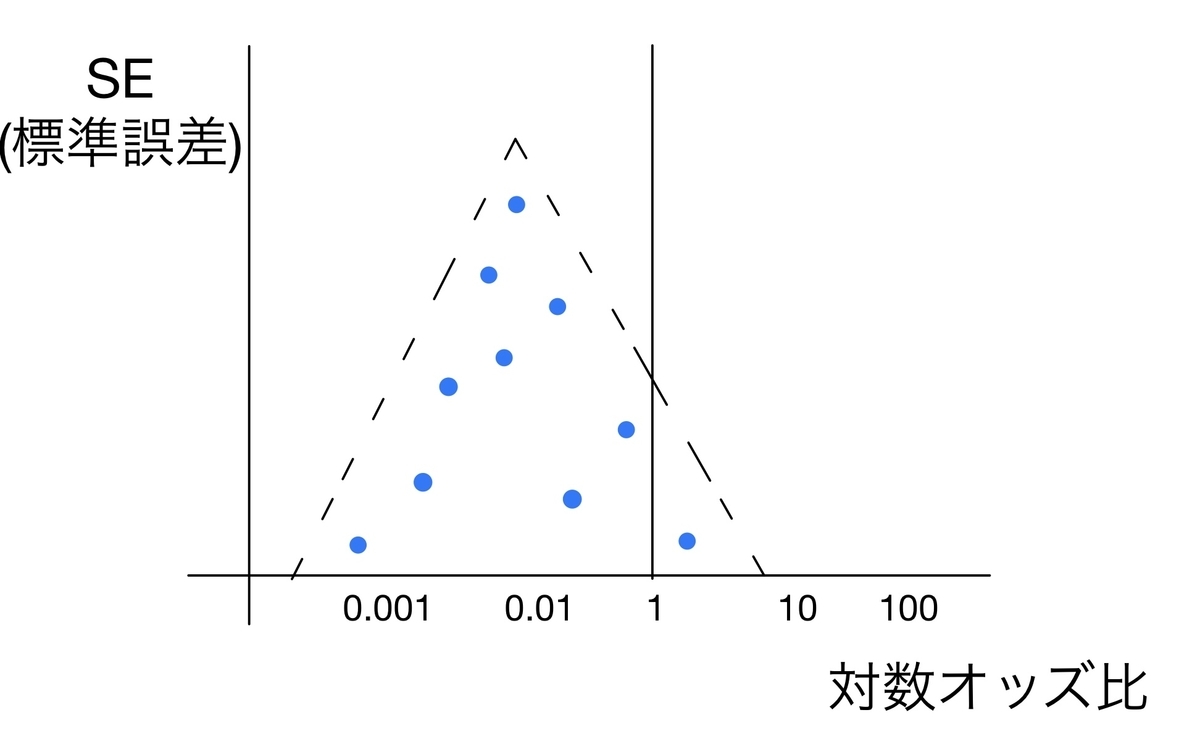
この図にどういう意味があるかというと、上に行けば行くほどサンプルサイズの大きい研究の結果になるため、より真の効果の値に近いことが予想され、下に行けば行くほどサンプルサイズが小さく効果の“ブレ幅“が大きいことが予想されます。
そのため報告バイアスや各研究の内容に問題がなければ、プロットはキレイな左右対称の三角形を描くと考えられます。

しかしながら、funnel plotが対称だったとしても必ずしも報告バイアスの問題がないとは言えないとされています。結構controversialな問題なんですね。
特に、研究数が少ない場合は注意が必要です。例えば研究が2つだけであれば、対称性はあまり分かりませんね。経験則的には10以上の研究があることが望ましいと言われています。
また逆に、報告バイアスや各研究内容などの問題が明らかにある場合は、対称性が崩れてしまいます。

こうなると報告バイアスなどの問題が生じている可能性が高く、メタアナリシスとしての評価は下がります。
funnel plotが対称であるかどうかは上図のように見た目でもある程度分かりますが、統計的仮説検定の方法を取ることもできます。以下で簡単に見てみます。
funnel plotの検定
funnel plotにおける検定では対称になっているかどうかのP値を算出します。
Egger's testやBegg's testと呼ばれる検定手法が代表的です。順位相関係数を利用したり、正規分布化したりして検定を行うようですが、詳細な数学的内容についてはすみませんが理解が十分でないため触れません。
結局のところfunnel plotと同じ発想で行われる検定であるため、偏りを評価する方法としては意味が大きく変わるものではありません。また、検出力が十分でないことも多いとされています。
ではこういった検定で有意差がついてしまう=funnel plotで非対称性となるのはどういう場合が考えられるのでしょうか。
funnel plotの非対称性
funnel plotが非対称となる場合には、以下のような点に問題がある可能性があります。
・報告バイアス
・研究の異質性
・研究デザインの質
・捏造
・偶然
まずひとつは、最初に触れたようにfunnel plotを描く目的でもある「報告バイアス」が存在する場合です。
報告バイアスがあると、基本的には”ポジティブ”な結果が出やすくなるため、介入が良い結果をもつ研究が多くなります。そうなるとプロットしたときに片側に点が固まりやすくなり、funnel plotが非対称となってしまいます。これを確認するのがfunnel plotをみる主な目的でした。
次に「研究の異質性」についてです。
前々回の記事で書いたように、各研究の対象となる患者や用いられる薬剤の量、評価の方法などによって研究の効果の大きさは異なってきます(実臨床に役立てるメタアナリシスの読み方② -Background編〜Methods編前半 参照)。
そうなるとそれぞれの研究がみようと思っている”真の効果の値”は違ったものになってしまいます。その状況ではfunnel plotを作ったところで、みているものが違うので、仮に報告バイアスがなくても対称にはなり得ません。根本的なところに問題があると言えます。
ただこの場合、サブグループにわけてfunnel plotを作ると有効である可能性があります。例えば重症の患者には薬がよく効くがそうでない患者には効かない、というように対象となる患者層が違うため、効果の大きさが変わってしまっているとしたら、それぞれをわけてfunnel plotを作ることで解消される場合もあります。薬の用量や種類、アウトカムの計測方法などによって効果の大きさが異なるときも同様ですね。
続いて「研究デザインの質」の問題です。
観察研究や二重盲検がされていないなど、個々の研究の質が低くなってしまう場合は当然のことながら、そのブレは大きくなりますし、あらぬ方向にバイアスがかかってしまう可能性もあります。そうなるとfunnel plotは対象にならなくなります。仕方がないので質の低い研究のみを省いてplotするという方法も考えられます。
また、論文の結果が「捏造」されている場合も他の研究結果と全く特徴の違うバラツキを見せるため非対称となり得ます。
そして最後に、「偶然」そういった偏りが生じてしまう可能性が0ではないことも認識しておかないといけません。
funnel plotにはこれらのさまざまな理由で歪みが生じうるため、非対称である場合にはなぜそうなったのかを論文内で吟味される必要があります。納得のいく説明があれば、エビデンスの質の点でもそこまで大きく下げずに考えて良いのではないでしょうか。
なお、funnel plotが非対称である場合、補正する手段として"Trim and fill method"という方法が行われている論文がありますが、現在はあまり用いられていないように思います。というのも実は結構マズイ方法と言えるからです。
この方法はfunnel plotが本来は報告バイアスがなければ対称になることを前提にして、対称になるように研究結果を補正する手法です。
非対称になる理由が純粋に報告バイアスのみであればそれも成り立つのでしょうが、このように複数の理由でなっていることを考えると、研究の異質性が高い場合やそれぞれの研究の質が異なってくる場合、対称性を前提とすることに無理があります。その点であまり推奨すべき方法ではないと言えるでしょう。
まとめ
・報告バイアスには多数の種類があることを認識する
・報告バイアスの対処のためには網羅的な検索
・報告バイアスの評価のためにはfunnel plot
・funnel plotは複数の理由で非対称になりうる
思った以上に長くなってしまいましたが、報告バイアスの対処と評価を中心にここまで述べてきました。結局のところ、報告バイアスを完全に対処できる手段はなく、評価も正確にはできないという点で、メタアナリシスにとって最大の問題と言われているのだと思います。ましてこの対処や評価すらきちんとできていないメタアナリシスは質において相当大きな問題を抱えているといえます。
正しいと思われることを見つけ出すのは非常に困難なことですね、、。次回は各研究の評価に焦点を当てた"risk of bias"を中心に調べて書いていきます。
次の記事はこちら
【医療統計YouTube】仮説検定とP値【第5回】
今回は“統計学的に有意“とは何かを説明するのに必須な仮説検定とP値の話をまとめました。
最初医療統計の本を読み始めたときに、特に理解しにくい部分だったように思います。ただ、これを理解していないと、大部分の論文で何をやっているのか分からないので、前回の推測統計の話とセットで必ず知っておきたい話ですね。
今回はP値が小さくなる要因にはいろいろあることを述べたわけですが、それ以外にもP値は誤解を生みやすい要素が多くあるので注意が必要です。
P値はあくまで「帰無仮説が正しいという仮定での“条件付き確率“」なので検査・診断における事前確率/事後確率の話と同様に、仮説の事前確率がどの程度なのかで仮説の正しさが変わってきます。
「P値が0.03=雰囲気的に97%くらい対立仮説が正しい」というわけでは全くないことも知っておきたいですね。またこの辺は改めてまとめ直した方が良いかもしれません。BMJのこの記事が参考になります。
次回はとにかく誤解を生みやすいワード「標準誤差」を見ていく予定ですが、ちょっと間で別のものを挟むかもしれません。
実臨床に役立てるメタアナリシスの読み方③ -Methods編中盤①-
引き続きMethodsの読み方について考えていきます。
ここでは「臨床的疑問に対する直接的な研究か」「複数名のレビュアーで文献が選択されているか」の2点について考えていきます。
前回までの記事はこちら
実臨床に役立てるメタアナリシスの読み方① システマティックレビューとメタアナリシスの違い『なぜメタアナリシスのみはダメなのか』
実臨床に役立てるメタアナリシスの読み方② -Background編〜Methods編前半
まとめたページと参考文献はこちら
目次:
臨床的疑問に対する直接的な研究か
これは「臨床への適用」を考える上で特に重要になってくる話です。
まず読み手としては持っている臨床的疑問に対して、メタアナリシスの結果として効果がどの程度かを確認していくわけです。しかしながら、メタアナリシスの効果を直接患者さんに適用しようと思っても、患者さんの状態や治療薬の内容や量、アウトカムの内容が違ってしまっては、予測される効果はメタアナリシスの結果からずれてしまいます。
では何がどうずれることが問題なのでしょうか。
これも前回同様にinclusion/exclusion criteria, intervention, control, outcomeを見ながら考えていきます。
より具体的には
・対象による薬の効果の違い
・プラセボ対象/実薬対象の違い
・エンドポイントの違い
の3点に着目します。
この辺の話はランダム化比較試験の読み方にも共通することなので、論文の読み方関係の本でもよくみるかもしれません。
集めようとした文献の基準はMethods, 実際に集まった文献はResultsに書かれていますので、今回の項目は両方を眺めながら検討していきます。
対象による薬の効果の違い
inclusion/exclusion criteriaを読むと大体の患者層が分かりますが、それが実際の患者さんと一致するかどうかが重要です。高齢者であれば薬剤の代謝が異なって同じ量でも強く効いてしまう可能性があります。また、病気の重症度や時期が異なれば、効き目がまるで違う場合もあります。
他にも高齢者の多い日本において、問題となるのは競合リスク(competing risk)の問題です。競合リスクの問題とは複数の種類のイベントがある場合、最初に起きたイベントしか観察できないという問題を指します。
例えば、脳梗塞と死亡、という複数のイベントがあったとき、当たり前ですが死んでしまったら脳梗塞は起きません。
つまり110歳の方を対象にアスピリンを内服させて、その後10年間に脳梗塞の再発があるかどうか調べた試験があった場合、10年間の脳梗塞再発を100%防げるなんて可能性もあるわけです。なぜなら寿命を考えると、脳梗塞再発よりも前に亡くなる確率が高いため、脳梗塞再発が確認できる確率はかなり減るからです。これが競合リスクの問題です。
患者さんに適用する場合にもこの問題は起きます。例えば50歳代の患者さんに抗凝固薬を飲ませて「2年間の脳梗塞の再発率が6割減りました」という試験があったときに、90歳代の患者さんに同じ薬を飲ませて、同様の効果は得られるでしょうか。おそらくそれは無理でしょう。実際に適用するうえではこのように他に起きうるイベントについても考慮しなければいけません。

図:競合リスクの問題
また少し直接的な薬の効果からは離れますが、一般的に臨床試験に組み込まれる患者さんは、①理解度がよい、②コンプライアンスが良い、③合併症が少ない、④大規模な治療施設に通院している、などの傾向があります。実際の患者集団よりもアウトカムの数値が良くなる可能性があるわけです。
さらにホーソン効果といって、試験として結果を期待されていると思うと、結果を良くしようと頑張ってしまう可能性もあります。総じてアウトカムが良くなりやすいことを考慮しておかないといけません。
プラセボ対照か実薬対照かの違い
この項目はintervention/controlの部分をみて検討していきます。
メタアナリシスに含まれる試験はプラセボ対照の試験を集めることが多いと思います。実薬対照だと統合する際の効果の比(あるいは差)がプラセボとは異なったものになってしまうためです。通常は、実薬との差の方がプラセボよりは小さいものになるでしょう。
ただ、実際の場面で患者さんは別の薬Aを飲んでいて、新しく別の薬Bに切り替えたい、という場合が想定されます。その場合は本来AとBを比較した研究がたくさんあればメタアナリシスで統合した結果を参考にできるのですが、実薬対照の研究は基本的にそんなにたくさんありません。二つを比較して優劣がついた場合、何度も同様の研究を行うのは倫理的に問題が生じるからです。
では、薬Aとプラセボを比較した試験のメタアナリシスと薬Bとプラセボを比較した試験のメタアナリシスの結果を見比べればよいのかというと、それはダメです。
大抵の場合、対象となる患者層が異なっているため直接的に数値を比べることはできないからです。
ネットワークメタアナリシスという方法論ではこれらをそれぞれ比べることも為されますが、エビデンスの強さという面ではやや信頼性に劣ります。
以上のことから薬の切り替えを想定する場面では臨床的に適切な回答は得られにくいと考えられます。
エンドポイントによる違い
この項目はoutcomeの欄を確認していきます。そこでみるべきポイントは“代用エンドポイント”かどうか、“エンドポイントはハードなのかソフトなのか”という点です。順番に説明していきます。
まず試験の結果として示されているエンドポイントが本当に意味のあるエンドポイントではない場合、期待された効果が得られる保証がない点に注意しないといけません。
例えば、60代の糖尿病の患者さんへの経口糖尿病薬で心血管イベントの抑制をしたいと思ったとしましょう。
その時、調べた経口糖尿病薬の試験のエンドポイントは「HbA1cを下げる」だったとします。
果たしてこの試験の結果をみて、心血管イベントの抑制は期待できるでしょうか。
必ずしも期待はできません。「HbA1cを下げれば糖尿病が良くなっているわけだから、心血管イベントは絶対に減る」という発想は正しくないと言われています。
例えば有名な例としてDPP4阻害薬のSitagliptinでの心血管イベント抑制をみたランダム化比較試験をみると分かります。
Effect of Sitagliptin on Cardiovascular Outcomes in Type 2 Diabetes
HbA1cは低下していますが、心血管イベントは減っていません。
この問題は結構難しいもので、例えば血圧についても同様な指摘が考えられます。血圧の数値を下げる作用が強いからといって必ずしも心血管・脳血管イベントの抑制や腎機能悪化に良いわけではないわけですね。
ここで出てきた「血圧」や「HbA1c」などの望まれる直接的なエンドポイントの代わりとして使われるものを”代用エンドポイント(surrogate endpoint)”といいます。
代用エンドポイントと望ましいエンドポイント同士の密接な因果関係が示されていればよいのですが、実際それを示すのは難しい場合が多いです。
最近の脳神経内科界隈では話題のアルツハイマー型認知症に対する薬”アデュカヌマブ”が承認された1番の理由はまさにその代用エンドポイントによるものです。
認知機能スケールの低下を抑制するという望ましいエンドポイントでは、過去の2つの研究データを組み合わせる(しかも中間解析で中止になっている)という荒業で有意差を出したに過ぎませんでした。その差も小さいものに留まっています。
ですが、FDAが承認した主な理由はアミロイドPETによってみられるアミロイドプラークの減少で治療効果が期待できるから、というものです。これで迅速承認(accelrated approval)しています。まさにこれこそ”代用エンドポイント”です。本来のエンドポイントのほうが重要視されるべきであることは言うまでもありません。
これまで同様の機序の薬が数々失敗してきたことを考えると、この代用エンドポイントが望ましいエンドポイントと密接な関係があるかと問われると、、、悩まざるを得ないところがあります。
この辺の話題は友人のブログが十二分にまとめてますので、興味があればこちらをどうぞ。
期待の新薬?アデュカヌマブが抱える現実的問題 12 選-エビカツ横丁
このように代用エンドポイントは必ずしも本当に患者さんのためになるものではない可能性があります。メタアナリシスで統合された結果が代用エンドポイントである場合、その目の前の患者さんに大した意味を持たない可能性もあることを踏まえて考えないといけません。重要なエンドポイントで効果が証明されている薬と代用エンドポイントでしか効果が証明されていない薬が選択肢にあるのであれば、前者をぜひ検討したいところです。
また、同様に問題となるのはエンドポイントがソフトかハードかという問題です。
ソフトエンドポイントというのは評価者によって変わりやすい性質のあるエンドポイントを指します。例えば「脳梗塞における麻痺の悪化」なんていうのは中々困ったエンドポイントです。NIHSSなどのスコアリングで示すなら良いですが、麻痺が悪化したかどうかというのは微妙な差である場合、評価者によって意見が変わる可能性があります。
「心不全入院」も心血管関連の研究でよくみるアウトカムですが、入院の基準が明確でない場合は、人によって判断が変わってしまうため、ソフトな面も生じてしまいます。
逆にハードエンドポイントは、人によって評価が変わりえないものを指します。究極的なものは「死亡」です。追跡できている限り「死亡」は人によって評価が絶対に変わらないものなので、強いハードエンドポイントとなります。
統合された結果がソフトエンドポイントに近ければ近いほど、患者さんにおいて同様の効果が得られるかどうかは不確実なものになっていきます。
複数名のレビュアーで文献が選択されているか
続いては、methodsに必ず書いてあるレビュアーの人数と文献の選び方についてです。
前回記事で述べたように、システマティックレビューでは文献を選別する基準が設けられています。ただ、その基準に当てはまるかどうか微妙なラインの研究が存在することが実際あります。そうした時に、一人のレビュアーが線引きをしてしまうとどうなるでしょうか。
そのレビュアーが自分が研究して推奨している仮説を支持するような論文を選んでしまうかもしれませんし、COI(利益相反)のある企業の薬を推奨するような論文を選んでしまうかもしれません。こうした偏りのことを評価者バイアスと呼びます。
メタアナリシスはどうしても事後的な解析になるため、バイアスを避けることが何よりも重要になってきます。そこで、迷った時は複数のレビュアーで文献を選別するような仕組みがあればより安心できると言えます。
論文によっては2人で吟味し、さらに意見が異なった場合は別の1人と相談する、という方法をとっているものもあります。複数人で評価されているということは最低限保障されないといけないと思われます。
まとめ
・臨床との患者層と薬剤の違いには要注意
・代用エンドポイント/ソフトエンドポイントかどうかを確認すべし
・評価者バイアスを意識しよう
次回の記事ではメタアナリシスにおける最大最強のバイアスである「報告バイアス(reporting bias)」を中心に書いていきます。
次回の記事はこちら
実臨床に役立てるメタアナリシスの読み方② -Background編〜Methods編前半
今回の記事ではBackgroundから順番に進めつつ、メタアナリシスの読み方を考えていきたいと思います。
前回の記事はこちら
実臨床に役立てるメタアナリシスの読み方① システマティックレビューとメタアナリシスの違い
メタアナリシスの読み方のまとめページはこちら
今回は「その臨床的疑問には本当に意義があるかどうか」 「各研究は統合可能なものか」という点に着目して、Background~Methodsの前半を中心にどう読むと良いか考えていきます。
目次:
その臨床的疑問は本当に意義があるか
まず、Backgroundでは
「その文献が問うている臨床的疑問は何か、本当に重要なものなのか」
という点に着目します。これは「臨床への適用」に関して重要な話題です。
ご存知の方も多いかと思いますが、臨床的疑問を定式化する方法として「PICO(PECO)に沿って整理する」というやり方があります。
PICOとは
P (Patient, 被験者)
I (Intervention, 介入)
C (Control, 対照)
O (Outcome, 結果)
の略を指します。研究の方法によってはIがE (Exposure, 暴露)に変わり、PECOが用いられる場合もあります。
Backgroundにおいて、その疾患や治療・診断の重要性、また治療の機序などが論じられますが、大抵の場合終盤に対象としている臨床的疑問が書かれます。まずはそれをPICOに沿って整理してみましょう。
重要なのはそこで問いにしている臨床的疑問が「本当に役に立つ疑問かどうか」です。システマティックレビュー&メタアナリシスの場合、幅広く文献を集めることになるため、臨床的疑問の対象を「どこまでの範囲にするか」といった点に着目する必要があります。
例えば、「全てのがん患者に対して(P)、全ての抗がん剤投与群(I)とプラセボ群(C)を比較した時、5年生存率(O)はどう変わるか」という臨床的疑問はどうでしょうか。
明らかに範囲が広すぎますね、、、。そもそも実際に治療をするのはある程度診断されて、種類の定まったがんです。抗がん剤もそのがんの種類に合わせて使うものであり、どれかを適当に使うわけではありません。そうなるとこの臨床的疑問は実際には役に立たない疑問と言えます。
では次の例はどうでしょうか。
「発症1週間以内の脳梗塞の患者で(P)、抗血小板剤投与群(I)とプラセボ群(C)を比較した時、1ヶ月後のADLはどう変わるか」
これならある程度絞られた患者層となっており、実臨床に沿った内容になっています。脳梗塞は通常発症早期に来院することが多いため、「発症1週間以内」という点も現実的ですし、症状が安定してくるのが1か月ほどであるため、「1か月後のADL」というアウトカムも臨床的には有用であると感じられます。
これらのように設定されている臨床的疑問の範囲が、実際の現場に役に立つものかどうかをまう確認することが必要です。
なお実際、メタアナリシスは前回の記事でも述べたように事後的な解析であるため、アウトカムが複数用意されていることは多くあります。
その場合は、それぞれのアウトカムに対して実際の現場で役に立つ臨床的疑問に沿うものかどうかを吟味しながら見ていく必要があります。
各研究は統合可能なものか
続いてMethodsで書かれる内容に進んでいきます。まずは統合する研究の基準となるinclusion/exclusion criteria, intervention, control, outcomeをチェックします。
この部分は「批判的吟味」と「臨床への適用」の二つの観点で読むことができます。今回の記事では「批判的吟味」の観点から見ていきます。読むときに注目すべき点は「各研究が統合できるような同質なものかどうか」です。
そもそも「なぜ各研究は同質でないといけないのか」を考えてみます。
リンゴとオレンジを比べられるか
同質でない研究を統合してはいけない理由として、よく「リンゴ」と「オレンジ」を一緒にして比べられるか、という例えが出てきます。
リンゴ同士であれば「色合い」「味」「大きさ」「重さ」などそれぞれを比べることは可能ですし、その順番に並べたり、数値の比較・要約も可能です。
ですが、リンゴとオレンジを混ぜ合わせてみたらどうでしょうか。

図:リンゴとオレンジを混ぜ合わせた数値の要約
どれが一番大きくて、二番目に大きいのはどれか、なんていうことは比べてもしょうがないですし、すべての重さの平均や大きさの中央値がどうか、ということも意味を感じません。
ですが、困ったことに種類が違う=異質なものでも統合した数値を出すことはできます。なので、それらしい数値が出てくるわけですが、リンゴとオレンジが混ざった平均値を出されても役には立たないわけです。
研究の話に戻ってみます。例えば、ある研究における「脳梗塞の1週間以内の再発率」と別の研究における「脳梗塞の1か月以内の再発率」を混ぜて数値を出してはいけません。また、「脳卒中(脳出血+くも膜下出血+脳梗塞)の再発率」と「脳梗塞の再発率」も一緒にしてはいけません。当然すぎると思われますが、それは明らかに同質ではないからです。
「そんな全然違うものが混ざるなんてあるの?」と思うかもしれませんが、メタアナリシスのみのレビューなどではそういった杜撰なものも時折見受けられます。
では、リンゴとオレンジの違いは見てすぐわかりますが、研究においてはその同質性をどうやって考えるのか。次の内容で見ていきます。
各研究のPICOは同質か
繰り返しになりますが、Methodsには対象となる研究のinclusion/exclusion criteria, intervention, control, outcomeが記載されています。これら4つの要素が本当に統合しても良いと言えるくらい同質なものかどうかを考えながら読みます。それぞれ簡単に考えてみましょう。
inclusion/exclusion criteria (patients)
これらが全く異なるものだと、患者層が異なってしまうこととなり、その効果も変ってしまうこととなります。例えば若年者を対象にした研究と高齢を対象にした研究では同じ治療薬を使ったとしても、多くの場合高齢者で結果が悪くなることが想定されます。また病気の重症度が異なる場合も同様で重症例の方が治療でのアウトカムが悪く、軽症例の方が治療でのアウトカムが良いなどの問題が生じ得ます(その逆も起こり得ますがいずれにしても結果が異なるものを統合することが問題です)。
intervention, control
用量依存性に効果が高くなる治療薬であれば、試験ごとに用量が異なると、統合することでの問題が生じます。またコントロールについてはプラセボを使っているどうかの違いがあると、プラセボ効果分での差の違いが生じてしまい、両群のアウトカムの差は変わってしまうでしょう。さらに介入以外の治療がどうなっているのかも場合によってはアウトカムが変化する要因となり得ます。
outcome
統合の対象となる数値であるため、同じものでないと直接的に結果に影響が出ます。最も良いのは全く同じアウトカムですが、そうでない場合はある程度同等の変化を示すことが推測されなければいけません。
さらに内容が同じアウトカムだとしてもフォローアップの期間が異なると、当然発症率も異なります。その調整や区別がされているのかどうかも注意しなければいけません。
加えてアウトカムの判定がどう行われているのか。全例に検査がされているのか、それとも症状があったら検査しているのか、検査方法はどういったやり方なのか、こうしたことでも違いが生じます。
なお、連続変数のアウトカムで見たい内容は同じだけれど、計測の仕方のみが異なる場合にはstandardized mean difference(SMD)を算出するという方法で、数値を標準化して比較する場合もあります。SMDは以下の式で算出されます。
SMD=各群のアウトカムの平均の差/アウトカムの標準偏差
こうするとその試験におけるアウトカムの差が、参加者全体の集団において何SD分に当たるのかがわかります。テストにおける偏差値と似たような考え方ですね。同様の数値はeffect sizeと呼ばれていることもあります。
例えば、認知症のstudyではMoCA, MMSEといった認知機能について複数の計測方法が知られており、studyによってわかれます。同じものを評価するのに計測の仕方が違うのみで統合できないと勿体無い話です。そこでSMDを用いて統合してみるわけです。
認知症のスケールを統合した例としては降圧と認知機能の変化を調べたこちらの論文などがあります。
ただ、この考え方も一部問題はあって、同じ1SDと言っても、対象としている試験の集団のアウトカムの数値が大きく異なってしまうとそれぞれの試験で別物になってしまうため、被験者集団の均質性がなければ結局違うものを統合していることになることに注意が必要です。
図でまとめる
大まかに図でまとめ直すとこのようになります。

これらの4つの要素(inclusion/exclusion criteria, intervention, control, outcome)が全く同じは無理にしても「アウトカムがある程度同じ数字にはなるだろう」と納得できるだけの同質性は必要だと思われます。
なお、システマティックレビューでは実際に文献を集めて、これらの4つの要素がどのようなものが集まったかは”Results”に記載されます。「臨床への適用」という観点では、実際に治療をしようとする患者さんにその4要素が合致しているかどうかが大変重要です。このあたりは次回の記事で書いていきます。
同質性が妥当かどうかの決まった基準はない
ここがメタアナリシスの難しいところですが、これらの同質性がどこまでなら妥当かの明確な基準はありません。以後のResultsのところで”異質性(heterogeneity)”という数値が出てきますが、これはあくまで統計的な計算によって数値のばらつきがおかしいかどうかを見たものに過ぎず、上記のような各研究の中身が同質か異質かを検討できるものではありません。昔、自分はそういうことがわかるものだと思ってましたが、、、(汗
そのため読む側が各研究を統合しても良いのかどうか、吟味する必要があります。特に自分が臨床で実際出会う患者層や行っている治療法と大きく異なる研究が含まれる場合は、その結果が適用しにくくなるため、普段の臨床場面との違いに着目することも必要です。
ここで、統合して良いのかどうかを吟味する基準としてよく用いられるのは病態生理に基づいたものです。
例えば、脳梗塞のメタアナリシスを読むときに、介入に「アスピリン(抗血小板薬)」を用いた研究と「ワーファリン(抗凝固薬)」を用いた研究を統合することには違和感を感じますが、「アスピリン(抗血小板薬)」と「クロピドグレル(抗血小板薬)」ならば、ある程度納得できます。同じような理屈で「アテローム性」「心原性」の患者さんを一緒くたにするのは、納得できない点がありますね。
病態による同質性の推定はある程度は説得力のある方法であると言えます。多くの場合、Backgroundを読むと、薬剤の生理学的な機序や疾患の病態についても記載があるため、なぜ著者がその基準で研究を統合しようとしたのかが分かります。
また、過去のデータからそれぞれのアウトカムや介入方法において大きな差がみられなかったという経験的なデータも同質性を保証する一つの手段になると思われます。
ただ、こうした同質性の仮定はあくまで仮定に過ぎないため実際に同じような効果が得られるものかどうかは不明です。良いメタアナリシスではそれを踏まえて、サブグループ解析でさらに同種の薬に絞ったりして結果を出していることが多いので、さまざまな観点でみても一貫した結果が出ているかどうかも確認しておいた方が良さそうです。
まとめ
・主題となる臨床的疑問が自分の現場に使えるかを確認する
・各研究の同質性が肝要
・同質性には明確な基準がない
では、次回以降も引き続きMethodsについて掘り下げていきます。
次回の記事はこちら
実臨床に役立てるメタアナリシスの読み方① システマティックレビューとメタアナリシスの違い『なぜメタアナリシスのみはダメなのか』
メタアナリシスの読み方をまとめたページはこちら
実臨床に役立てるメタアナリシスの読み方まとめ - 脳内ライブラリアン
今回はまず前提知識として
①「システマティックレビュー」と「メタアナリシス」の違いは何か
②どのような流れでその2つが組み合わさるのか
の2点について書いていこうと思います。
目次:
システマティックレビューとメタアナリシスとは何か
システマティックレビューとその目的
古典的に医学分野でよく言われる定義として、システマティックレビューは「臨床的疑問に対し、再現可能な方法で系統的に文献を集め、結果を吟味したもの」と言えます。
対象とする臨床的疑問は診断、予後、治療、副作用など多岐にわたります。
もともと個々の研究もこうした臨床的疑問に答えるためのものですが、ひとつの研究だけではどうしても結果が偏ってしまったり、正しい結果が得られていない可能性があります。
そこで、過去の複数の研究を定めた方法に従って収集し、結果を吟味することで、より正しい結果を導こうとするのがシステマティックレビューです。
ここで肝心なのは「定めた方法で、系統的に」文献を集めるという点です。
著者の思いつくままに文献を集めるとすると、著者の思い込みやバイアスのもとに文献が集まってしまい、正しい結果が得られる可能性が低くなります。
特に、著者に何らかの主張があるとするとその主張に沿った文献が目につきやすくなるため反例となるような文献が集められにくくなります(確証バイアス)。
そうではなく、臨床的疑問に沿った質の良いデータが得られるように事前に方法を決め、それに沿って文献を集めることで、バイアスを避けることができ、また再現性も得ることができます。
ちなみに、ナラティブレビューと呼ばれる方法では、著者が恣意的に文献を集めるため、偏った結果が導き出される可能性が高くなります。ただ、これはこれで、その分野においてどんな文献があって、専門家(著者)の間ではどういった点が重要視されているのかをざっと掴みやすいため重宝します。
メタアナリシスとその目的
古典的な定義において、メタアナリシスは「得られた結果を統合すること」を指します。吟味された論文の結果を統合し、初めの臨床的疑問に対しての答えを出します。
結果が数値として明確に示されると臨床的な応用につなげやすくなり、より有用性が増すと言えます。
なお、今回の記事ではシステマティックレビューとメタアナリシスの違いをよく認識することが重要なので、分けて書きますが、実際のところ両者を合わせて「メタアナリシス」と呼ばれることも多いため、次回の記事ではそのように記載します。
システマティックレビューからメタアナリシスの流れ
図でまとめてみる
システマティックレビューからメタアナリシスまでの流れをごく簡単に示してみると、以下のような図になります。

順番に見ていきます。
①PICOに沿って集める
まず臨床的疑問をPICO(あるいはPECO、後述します)などの形式にし、同じ臨床的疑問に答える研究を網羅的に集めます。
この時点では質の低いデータや条件が異なるものなども混じっているかもしれません。
②データの抽出・選別
次にデータの抽出・選別をします。前述したように、これは好きに選ぶのではなく、予め方法をよく決めた上で、それに沿って選別します。
細かい点は今後の記事で説明しますが、質の低いデータを除いたり、試験の条件が大きく異なるものを除いたりしていきます。また各研究について"risk of bias"というバイアスの程度を評価していきます。
ここまでがシステマティックレビューで行われることです。
③結果の統合
集められた文献のデータを統合し、結果となる数値を出します。
これによって、ひとつの統一された値を推定することができ、治療などによる効果を具体的に割り出します。
またサブグループ解析として集められた文献の一部に絞って結果を出したり、感度分析として解析方法を変える、質の高いデータに絞る、などして結果の妥当性を検討します。
さらに可能であればNNT(number needed to treat; 何人に治療をしたら1人分のアウトカムが得られるか)、あるいはNNH(number needed to harm; 何人に治療をしたら1人分の害が出るか)を算出する場合もあります。
加えて、研究ごとの結果の違いについて説明可能な要因を見つけ、検討を行います。
この一連の流れに沿って行われる分析がSystematic review and meta-analysisと呼ばれるものです。
システマティックレビューがきちんとしていない場合
では、このシステマティックレビューがない、あるいはきちんとされていないとどうなるでしょうか。図で示すとこのようなものになる可能性があります。

データの抽出・選別の過程が恣意的な偏ったものだと、結果としては全く違ったものになります。
ここで質の低いデータが混ざれば、統合した際に結果の数値が誤った方向に寄ってしまう可能性が高くなります。質の低いデータとは観察研究や盲検化されていないランダム化比較試験など、バイアスが大きくなりやすいデータを指します。こうしたデータの質をよく考慮して統合する必要が出てきます。
また、試験の条件の違うデータをまとめてしまうと、実際は存在しない数値が生み出されるだけになってしまいます。例えば「対象となる年齢が20-40歳の研究」と「対象となる年齢が60−80歳の研究」をまとめるとどうなるでしょうか。それぞれの結果は対象者が全く違うため、まとめた結果の数値はただの架空の数値となってしまい、現実に応用はできません。
つまり、過去の研究を統合すればなんでも良いというわけでは決してなく、データの質や同質性をよく考慮してデータの選別・抽出を行い、統合しなければいけないわけです。というわけで、システマティックレビューの過程は大変に重要なものと言えます。
システマティックレビュー&メタアナリシスの問題点
ここまでの特徴を踏まえて、システマティックレビュー&メタアナリシスの問題点について見ていきます。
事後的解析である
システマティックレビュー&メタアナリシスは上の流れで見たようにあくまで過去にあった研究を「事後的」に抽出し、解析する手法です。
この「事後的」ということがどういう意味を持つかと言えば、恣意的に結果をいくらでもねじ曲げられるということですし、恣意的でなくても結果がねじ曲がることも起き得ます。特に抽出する方法にバイアスがあると容易に間違った結果が導き出されます。
各研究データの質に依存する
仮にこの抽出の方法が問題なかったとしても、そもそも元となる各研究データの質が低い、あるいは規模が小さければ、やはり間違った結果となってしまう可能性は十分にあります。
実際に、小規模な研究を集めたシステマティックレビュー&メタアナリシスが、のちに行われた大規模ランダム化比較試験によって結果を否定される例は散見されます。
参考文献に挙げた『臨床研究を正しく評価するには』において、頭部外傷におけるコルチコステロイドの静注の効果をみたCRASH trialやICUの重症患者におけるアルブミン投与の試験などが挙げられています。参考のためリンクも貼っておきます。
Corticosteroids in acute traumatic brain injury: systematic review of randomised controlled trials
こちらのメタアナリシスでは約2000名の頭部外傷患者が対象となっており、コルチコステロイドは有効という結果が出ていました。
それに対して約10000名を集めたランダム化比較試験では結果はひっくり返り、コルチコステロイド群での死亡率の高さゆえ、試験が中止される結果となりました。
また最近自分が実際に抄読会で遭遇した例として、消化管出血に対するトラネキサム酸の投与の試験があります。
Tranexamic acid for upper gastrointestinal bleedinghtt
2014年のコクランによるシステマティックレビュー&メタアナリシスでは約1600名の患者が対象とされ、有効性が示されました。
これに対して約12000名の大規模ランダム化比較試験では有効性が示されませんでした。もちろん有意差が出なかっただけなので「有効性が示されない=有効性はない」ではないのですが、ここまでの大規模で検出力も高いことを考えると少なくとも臨床的に大きな効果はないだろう、と推定されます。
規模の小さい試験ではどうしても結果の数値のばらつきが大きくなるため、メタアナリシスでそれらを統合したとしても、正しい結果が出るとは限りません。
メタアナリシスはエビデンスの頂点?
こうした誤りが起こりうる点を考えると、以前よく見られたエビデンスピラミッドという図はよくない印象を与えるものだと思ってます。

図:“メタアナリシスがエビデンスの頂点!“というやつです
適切な手法で行われていないシステマティックレビューやメタアナリシスはいくらでも間違った方向に導けますし、各研究データの質が低くても結果が誤る可能性はあるので、「メタアナリシス=エビデンスレベルが高い」という単純な式は全く正しくありません。こうしたイメージがメタアナリシスの盲信を生んでしまうのではないでしょうか。
実際医学に限らず、教育・心理学・脳科学関連の本でも何かと「これはメタアナリシスなので確実性が高い」かのように書かれているのを見ますが、一般向けに分かりやすくそう書いているとしても、中身を見ると実はお粗末なメタアナリシスということがままあります。
メタアナリシスの中でも、抽出する方法にどう問題があるといけないのか、臨床に適用する上での注意点を中心に今後の記事で述べていきたいと思います。
まとめ
・システマティックレビューは同質で質の良い研究データを抽出する
・メタアナリシスは結果を統合する
・適切なシステマティックレビューがないとバイアスが生じ得る
・メタアナリシスの質はデータの抽出過程と元の研究の質次第
続いてはBackgroundから注意点を挙げつつ順番に読み進めていきます。
なお、次回からはより分かり易いことと必要性の高さから「治療」におけるシステマティックレビュー&メタアナリシスを中心に述べていきます。また、メタアナリシスはランダム化比較試験の集合体であることが多いため、ランダム化比較試験(RCT)の質の評価についてある程度わかっていないと、批判的吟味もしづらいように思います。事前にそれがわかった上で読んだ方が分かりやすい内容になるかもしれません。
次回の記事はこちら
実臨床に役立てるメタアナリシスの読み方まとめ
以前にも一度システマティックレビュー&メタアナリシスについてまとめようとしたことがあったのですが、部分的な説明止まりだったので改めて書いてみることにしました。
医学論文の読み方を解説した本ではランダム化比較試験、観察研究などの説明が多く、メタアナリシスについて書いた本は少数で、取り上げているとしても分量が少ないです。研究をする側に向けた本は多数ありますが、逆に専門的すぎて読む側としては難しすぎるきらいがあります。
そこで、読む側に向けて「臨床への適用」+「批判的吟味」を中心に調べた内容をまとめます。実際に論文を読むことを考えて、Background-Methods-Results-Discussionの順に注意する点を記載していきます(一部順番は前後しますが)。
例によって疫学等が専門ではないので気になる箇所等あればご指摘いただけますと幸いです。
随時更新した記事をここにまとめていく方式とします。
参考文献もこちらにまとめますので、より詳しく知りたい方は参考にどうぞ。
(最終更新 2021/11/26)
前提知識
Background編
Method編
異質性の評価はされているか(補足として固定効果モデル・ランダム効果モデルの話)
Results編
Discussion編
参考文献:
リンク
『JAMA User's Guide to Medical Literature』
普及しているとは思えないですが、エビデンス関連の本の中で個人的に最も勧めたい1冊。観察研究からランダム化比較試験、メタアナリシスからネットワークメタアナリシスまで幅広くカバー。細かい数式などは使わずタイトルの通り、臨床に適用しようとする医学文献のユーザーのための本となっています。いずれの章も、実際の症例に使う場合どう考えるかを主題として解説している点も素晴らしいです。
内容が充実しすぎて通読は無理ですし、未だにしてませんが、抄読会などで論文を読む際に参考にするとよいと思います。
リンク
『医学文献ユーザーズガイド』
邦訳版です。英語が平易なのと訳がかえってややこしいところがあるので、 英語版でもよいですが、苦手な方はどうぞ。
リンク
『メタアナリシス入門』
メタアナリシスの統計数理的背景を解説した本です。序盤までしか読んでませんが、統計やる人向けですね。『統計学のセンス』を書かれた著者の方で、文章や数式の解説は分かりやすい方なのではないかと思います。とはいっても現在の知識レベルでは難しいです(汗
リンク
『臨床研究を正しく評価するためには』
「ランダム化比較試験の長所短所は?」「バイオマーカーは薬効評価において有効?」など26個のギモンに答える形式で臨床研究について書かれた一冊です。大事なポイントがコンパクトに収まっており、他の本で敷居が高いと感じた人にもお勧めできます。メタ解析については1章割いてあるのみですが、参考になります。
リンク
『医学論文を読んで活用するための10講義』
薬剤師青島先生が書かれた医学論文の活用のための一冊です。こちらも一部ですがメタアナリシスの読み方について触れられています。参考にさせて頂きました。
以下は論文などのページリンクになります。
Cochrane共同計画の公式ページやjournal of epidemiology、BMJのサイトは無料で読める部分も多く非常に参考になります。より詳しくそのままの情報を知りたい方はぜひどうぞ。
Chapter 8: Assessing risk of bias in a randomized trial | Cochrane Training
Cochrane methodology | Cochrane Training
システマティックレビュー&メタアナリシスにおける大御所であるCochrane databaseのトレーニングページです。risk of biasの評価法やGRADEシステムの解説などがされており、エビデンスの質をどう評価するのかが理解できます。文章量も非常に多いので、一部のみ参考としています。
Reporting Biases | Cochrane Bias
上記のCochrane handbookにおける報告バイアスのページです。
Chapter 8: Assessing risk of bias in a randomized trial | Cochrane Training
上記Cochraneのrisk of biasのページです。
Chapter 10: Analysing data and undertaking meta-analyses | Cochrane Training
上記Cochraneの結果の統合についてのページです。フォレストプロットの例も載っています。
Journal of clinical epidemiologyのGRADEシステムの解説をしたシリーズです。研究の質の評価という点でかなり厳格に詳しく書いてありますので、本格的に読みたい方にはお勧めです。つまみ読みしたので上げていますが、正直十分には読めておりません。
GRADE guidelines: 4. Rating the quality of evidence—study limitations (risk of bias)
上記シリーズの中のrisk of biasの話です。
GRADEシステムの日本語解説ページです。
funnel plotについて掘り下げた解説論文です。
システマティックレビュー&メタアナリシスにおいて著者が従うべきPRISMA statementのページです。読む側としても、どの点が欠けていると問題なのかがわかるためチェックリストなどは参考になります。
PRISMA2020の項目の個々の説明はこちらにあります。
公表バイアスを中心に数式の理解について書いた日本語の総説です。
2014-2021年の統計検定1級の出題範囲をまとめてみた(統計数理+医薬生物学+共通問題)【統計検定1級対策】
さて、そろそろ統計検定1級まであと3ヶ月となりました。
勉強時間が取れなさすぎて間に合うか不安しかないです(汗
そこで、ある程度は分野の重みづけをして勉強したほうが良いと思われますので、ここで改めて過去6年間の問題を見直して、出題された内容をキーワードにしてごく簡単にまとめてみました。一応2014年以外は一通り解いてます。
統計検定の受験を考えている人の訪問が結構あるようなので、ざっと眺めて参考にしていただければ幸いです。そして今年の問題のよい予測があったら教えてください、、、(笑
統計検定対策の記事やお役立ちサイト・参考書はこちらにまとめてあります
統計検定1級の出題範囲と過去の記事・お役立ちサイト・参考書をまとめてみた
(2021.09.02 共通問題の出題範囲を追記しました)
(2021.11.22 2021年の出題範囲を追記しました)
統計数理
統計数理は出題されている確率分布を中心に書いておきます。
2021年 統計数理
問1 指数分布 一様分布 確率変数の積と和
問2 超幾何分布 ベイズ法
問3 ポアソン分布 和の再生性 十分統計量 最尤推定量 信頼区間
問4 分布は規定なし 標本分散 平均まわりのモーメント
2020年はCOVID-19流行のため中止
2019年 統計数理
問1 二項分布 確率母関数
問2 指数分布 確率関数の和 変数変換
問3 一様分布 十分統計量 不偏推定量 完備十分統計量
問4 コーシー分布 仮説検定 α,β(検出力) 尤度比検定
ネイマンピアソンの補題
問5 ベイズ推定 事前分布 事後分布
2018年 統計数理
問1 カイ二乗分布 標本分散 不偏推定量 コクランの定理 デルタ法
問2 超幾何分布 期待値 不偏推定量 漸近分散 デルタ法
問3 二項分布 条件付き確率変数 条件付き期待値 条件付き分散 最尤推定 モーメント法
問4 正規分布 条件付き分布 条件付き期待値 条件付き分散 マルコフ性
問5 一様分布 順序統計量 同時確率密度関数 期待値 分散
2017年 統計数理
問3 ポアソン分布 二項分布との関連 モーメント母関数 確率変数の和 正規近似
2016年 統計数理
問1 正規分布 尤度関数 最尤推定量 バイアス 不偏推定量 最小二乗誤差 フィッシャー情報量 クラメール・ラオの下限
問2 指数分布 仮説検定 最尤推定量 不偏推定量 確率変数の和 カイ二乗分布
問3 線型モデル 最小二乗推定 算術平均と調和平均 コーシー・シュワルツの不等式
問4 正規分布 乱数生成 二項分布 一様分布
問5 MCARの検定(誘導の元で) 一元配置分散分析
2015年 統計数理
問1 正規分布 k次モーメント 不偏推定量 不偏分散の一致性 平均二乗誤差
問2 正規分布 P値 検出力 サンプルサイズ計算 ネイマンピアソンの補題
問3 重回帰分析 正規方程式 偏回帰係数の推定量の分散 偏回帰係数の推定量の最小二乗誤差
問4 2×2分割表 期待度数と観測度数 期待度数の最尤推定 尤度比検定
2014年 統計数理
問1 一様分布 条件付き確率 順序統計量
問2 ガンマ分布 モーメント母関数 変数変換(複数) 同時確率分布 順序統計量
問3 正規分布 仮説検定 z検定・t検定(分散未知/既知それぞれ) 信頼係数 区間推定
問4 線型モデル 正規方程式 最小二乗推定量 非心カイ二乗分布
問5 多項分布 尤度関数 適合度検定 尤度比検定
雑感
・ベイズは2019年が初出ですね。必要性の高まりを考えると今年も出そうですが、流石に出るとしても1−2問だと思われるので、可能なら回避する予定です。慣れないので、、、。
・出る分布は大体決まっている感じで、コーシー分布などの分布になるとちょっとしたヒントが一緒に出されます。(tanの逆関数を微分するとよいとか)
一様分布、二項分布、ポアソン分布、超幾何分布、指数分布、正規分布、カイ二乗分布、ガンマ分布あたりは確実に抑えておきたいです。
・不偏推定、最尤推定などの点推定や条件付きの問題も安定してよく出ています。
・デルタ法も汎用性の高さから、 よく問われているのでいろんな場面での使い方を抑えておきたいところです。確率変数を用いた関数の期待値、分散や漸近分布に対しての使い方とか。
統計応用(医薬生物学のみ)
統計応用は医薬生物学のみ書きます。出題されている内容と確率分布を頭に持ってきて書いておきます。
2021年 統計応用(医薬生物学)
問1 生存時間解析 カプランマイヤー法 競合リスクモデル
問2 正規分布 複合仮説による仮説検定 信頼区間 対数正規分布
問3 2×2分割表 オッズ比の推定 積二項尤度 カイ二乗分布
Cochran検定
2020年はCOVID-19流行のため中止
2019年 統計応用(医薬生物学)
問1 生存時間解析 指数分布 カプランマイヤー法 ネルソンアーレン推定量 RMST法
問2 前向きコホートでの再発比較 二項分布 信頼区間 共変量での層別化 傾向スコア バランス特性
問3 検査法の比較 二項分布 多項分布 感度・特異度 陽性的中率・陰性的中率 多変量正規分布の分散共分散行列 デルタ法 仮説検定
問4 対応のない2標本の検定 Studentのt検定 Wilcoxonの順位和検定
2018年 統計応用(医薬生物学)
問1 生存時間解析 指数分布 尤度関数 フィッシャー情報量 最尤推定 仮説検定 サンプルサイズ計算
問2 治療有効率の比較 多項分布 正規近似 信頼区間 尤度比検定
問3 感度・特異度 陽性的中率・陰性的中率 ROC曲線 c-statistic
問4 ロジスティック回帰分析 二項分布 調整オッズ比 AIC Kullback-Leibler情報量
2017年 統計応用(医薬生物学)
問1 生存時間解析 ハザード関数 Cox比例ハザードモデル 一様分布からの乱数生成
問2 中間解析(α消費関数法) 2変量正規分布 ログランク検定(内容は問われていない)
問3 simonの2段階デザイン 二項分布 第1種・第2種の過誤 サンプルサイズ計算
問4 層別化された後ろ向き研究 オッズ比 Petoの方法
2016年 統計応用(医薬生物学)
問1 対応のある2標本の検定 t検定 符号検定 符号付き順位検定 符号検定の正規近似 符号付き順位検定の正規近似
問2 治療有効率の比較(4種) カイ二乗分布 コクラン・アーミテージの傾向性検定
問3 生存時間解析 カプランマイヤー法 ログランク検定 部分尤度
問4 薬物血中濃度のAUC 対数正規分布 モーメント母関数 変動係数 信頼区間
2015年 統計応用(医薬生物学)
問1 治療有効率の比較 カイ二乗検定 多項分布
問2 超幾何分布 フィッシャーの直接確率計算法
問3 回帰分析 偏回帰係数の最尤推定 偏回帰係数の最尤推定の分散共分散行列
問4 前向きコホート研究 有害事象の差 二項分布 ロジスティック回帰分析 調整オッズ比
2014年 統計応用(医薬生物学)
問1 治療効果(連続変数)の比較 カイ二乗分布を用いた検定
問2 平均への回帰 2変量正規分布による仮説検定
問3 陽性的中率・陰性的中率 正規分布 感度・特異度 ROC曲線のAUC
問4 生存時間解析 指数分布 MST λの最尤推定
雑感
・バラエティに富んでいて、傾向が掴みづらいですね、、。特に直近の2019年はどうにも見慣れない問題が多く、初見で解ける気がしませんでした。
・2標本(あるいは1標本)のt検定、ノンパラ検定の問題は比較的型に収まりやすいので、もし出題されたら確実に得点したいところです。各検定の特徴も問われるので抑えておきたいですね。
・生存時間解析もここのところ毎年出ている重要な分野です。これも大体型に収まってる気がしますが、RMST法は捻ってますね。知ってれば簡単ですが知らないとこれもまたミスしそうです。あとは出てない部分としてGreenwoodの公式あたりそろそろ出ないですかね。程よい難易度になると思うので。
・基本的にちょっと凝った概念(RMST法、傾向スコア、Simonの2段階デザイン、中間消費法など)でも誘導があるんですが、うまく誘導に乗れるかどうかが大問題です。あらかじめその概念を知っておけると楽なのでしょうが、現実的にはなかなか難しいですね。
統計応用(共通問題)
2021年 統計応用(共通問題)
問5 感度/特異度 陽性/陰性的中率 感度/特異度に合わせた閾値の計算
2019年 統計応用(共通問題)
2018年 統計応用(共通問題)
問5 混合分布 正規分布 二峰性
2017年 統計応用(共通問題)
問5 二項分布 漸化式 サンプルサイズ計算 二項分布の正規近似
2016年 統計応用(共通問題)
問5 2標本のt検定 95%信頼区間 信頼区間とt検定の関係
2015年 統計応用(共通問題)
問5 二元配置分散分析 P値 分散の最尤推定
2014年 統計応用(共通問題)
問5 独立性のカイ二乗検定 二項分布 超幾何分布
雑感
・基本的な事項を問う問題が多く、医薬生物学の応用問題よりは解きやすいものが多いように思います。誘導もそれなりについている点もありがたいです。数理統計の良い勉強になります。
・2019年の問題に出ている適合度検定における多項分布と正規近似、そこからの共分散行列、カイ二乗分布に結びつけていく部分は、よく見てみると医薬生物学の問題でも2回ほどは出ている概念です。程よい難易度で問題がいくつも作りやすいからかもしれません。多項分布に対してラグランジュの未定乗数法でパラメータの最尤推定をする、というのも出てますね。
・なんとなく苦手としている分野でなければ、医薬生物学から3問解くよりもここにチャレンジした方が良さそうな気がします。